How to Choose the Right AI Agent Framework
When we talk to founders and product teams about AI, the same question comes up again and again:
“Which framework should we use to build our agents?”
It’s a fair question. The ecosystem is crowded. LangGraph, CrewAI, Pydantic, Autogen — every week a new tool launches, each one promising to be “the future.”
Here’s the truth: there is no single “best” framework. There’s only the best one for your project, your team, and the way you want to grow.
At Itera, we’ve tested these tools in real projects — from logistics dispatch agents to HIPAA-compliant healthcare workflows. This guide is what we’ve learned: how to evaluate frameworks, where each one shines, and how to make a decision that won’t box you in later.
Why the framework matters
An AI agent isn’t just code. It’s a digital teammate. It plans, takes action, learns from mistakes, and (if built well) makes your team faster without burning them out.
The framework is the scaffolding that holds that teammate together. Pick the wrong one, and you spend months fighting bugs, rewriting logic, or patching integrations. Pick the right one, and you move faster, stay flexible, and can scale when things actually take off.
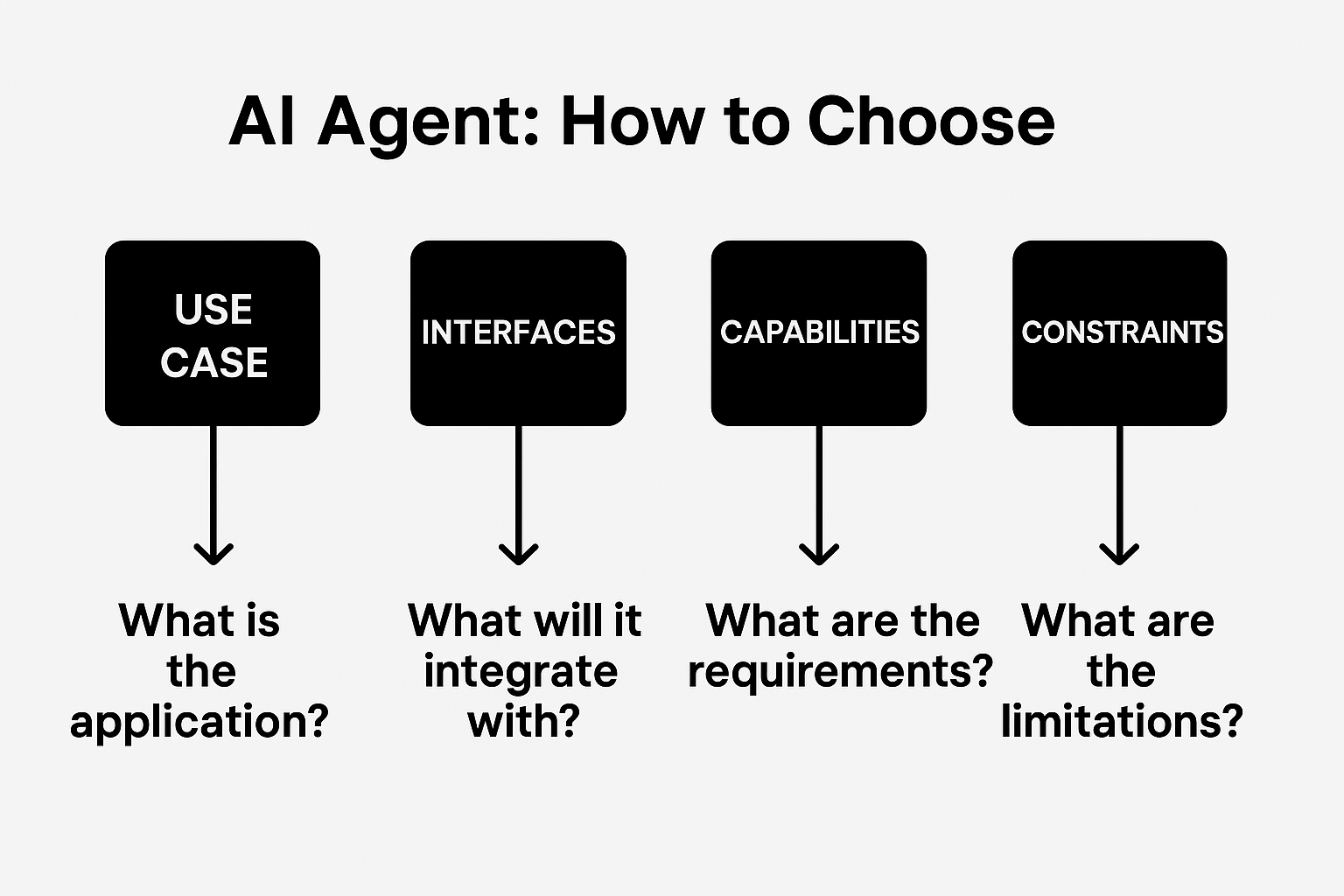
What to look for
When we evaluate frameworks for clients, we start with six simple questions:
-
How fast can we prototype? (Speed vs. complexity)
-
Will it scale if we succeed? (Workloads, multimodal input, multiple agents)
-
Does it integrate with our stack? (Python, TypeScript, cloud services)
-
Can we trust it in production? (Checkpoints, error handling, explainability)
-
Is there a real community? (Docs, support, active devs)
-
Does it fit the actual use case? (Not just the hype cycle)
Answer these, and the “choice” starts to get clearer.
Frameworks we’ve put to the test
LangGraph → Reliability at scale
LangGraph takes a different approach than traditional chain-based frameworks. Instead of forcing your agents to follow a strict sequence, it uses graphs — meaning workflows can branch, loop, or circle back when conditions change. This is powerful for real-world systems where tasks are rarely linear.
One of LangGraph’s biggest strengths is state management. Every step gets checkpointed, so you can pause, rewind, or debug without breaking the whole process. In production, that’s the difference between firefighting outages and calmly fixing an issue mid-run.
It also supports both Python and TypeScript, giving teams flexibility depending on their stack.
Best for: complex, mission-critical systems where predictability, debugging, and long-term reliability are non-negotiable.
Google AI SDK → Multimodal, enterprise-grade
Google’s SDK was built to make its Gemini models production-ready. That means agents that can handle text, images, audio, and video all in the same workflow — something most frameworks still struggle with.
It comes with pre-built orchestration patterns like sequential, parallel, and looping execution, which means you don’t need to reinvent coordination logic. On top of that, it integrates directly with Google Workspace and Cloud services: agents can fetch data from BigQuery, schedule events in Calendar, or edit a Doc without brittle hacks.
Another standout is explainability. The SDK doesn’t just tell you the agent’s output — it can explain why it reached that decision, which is critical in compliance-heavy industries.
Best for: enterprises already running on Google Cloud that need secure, multimodal AI with auditability built in.
CrewAI & AG2 → Agents working together
Some problems are too complex for a single agent. That’s where multi-agent orchestration comes in.
-
CrewAI works like a film crew: every agent has a role. You might have a researcher, a writer, and a fact-checker, each contributing their piece of the puzzle.
-
AG2 (AutoGen v2) is closer to a brainstorming session: agents exchange ideas, critique one another, and refine their answers until they converge on a solution.
Both approaches unlock new possibilities. For example, in market research, one agent can gather data, another can analyze it, and a third can summarize insights in plain English. The result feels more like a team of specialists than a single AI assistant.
Best for: projects where collaboration and perspective diversity matter as much as raw output — like strategy, research, or innovation workflows.
Pydantic AI → Structured & predictable
Pydantic AI builds on the Python library most developers already know for data validation. Instead of free-form outputs, it forces AI agents to stick to structured, type-safe formats.
That structure is invaluable in production. Imagine running an AI agent that feeds into a billing system. A single malformed output could trigger errors downstream. With Pydantic AI, outputs are validated automatically before they’re sent forward, reducing risk.
The trade-off: it’s less creative than other frameworks. But in industries like healthcare, finance, or compliance-heavy fields, predictability beats creativity every time.
Best for: developers who already rely on Pydantic and need accuracy, safety, and consistency in agent outputs.
Mastra → TypeScript first
While most frameworks lean into Python, Mastra was built from the ground up for TypeScript developers. That means the ecosystem feels familiar if your team already ships in JavaScript/TypeScript.
Mastra emphasizes developer experience: modular architecture, clear APIs, and built-in utilities for monitoring, tracing, and logging. It helps ensure that as your system grows, you don’t lose sight of what’s happening inside your agents.
For frontend-heavy teams or startups where the engineering stack is already JavaScript-centric, Mastra removes the friction of adopting yet another language.
Best for: product teams building in TypeScript/JavaScript ecosystems who want an AI agent framework that feels native.
Autogen → Lightweight & flexible
Not every team needs a heavyweight solution. Autogen keeps things simple by focusing on multi-agent conversations and tool usage without forcing you into a rigid structure.
It’s a great entry point because it’s lightweight, unopinionated, and quick to set up. That makes it ideal for experimentation — you can spin up agents, test interactions, and explore ideas without weeks of setup.
The flip side: it lacks some of the built-in reliability and orchestration features of frameworks like LangGraph. But if you’re in early R&D mode, that’s a trade-off worth making.
Best for: proof-of-concepts and experiments where speed matters more than robustness.
No-Code Options → Visual prototyping
Not every team has developers available. Tools like Flowise, Relevance AI, and Dust let you drag-and-drop agents together visually. Within minutes, you can connect models, tools, and data sources to see how they interact.
The big advantage is speed: stakeholders can test an idea without touching code. But the ceiling is low — once you hit complex requirements, you’ll need to switch to a code-based framework.
Best for: non-technical teams or early ideation, where the goal is to validate concepts before investing in engineering.
How to make the call
-
Building complex systems with high reliability? → LangGraph
-
Already a Google Cloud shop? → Google AI SDK
-
Need multi-agent teamwork? → CrewAI or AG2
-
Care about correctness above all? → Pydantic AI
-
TypeScript all the way? → Mastra
-
Just testing the waters? → Autogen or no-code
What we’ve learned
Every time we run a project, the same lesson comes back: The “right” framework isn’t the one with the most features. It’s the one that matches the problem, the team, and the timeline. Simple tech is rarely easy. But if it’s human-centered, it’s worth it.